A
argbe.tech - news1 min read
TensorRT-LLM AutoDeploy targets agent latency with a 3-step, automated path from PyTorch to optimized inference
NVIDIA added a beta AutoDeploy workflow in TensorRT-LLM that automates conversion and optimization from PyTorch to deployment-ready inference graphs. It supports NVIDIA Nemotron and more than 100 text-to-text LLM architectures.
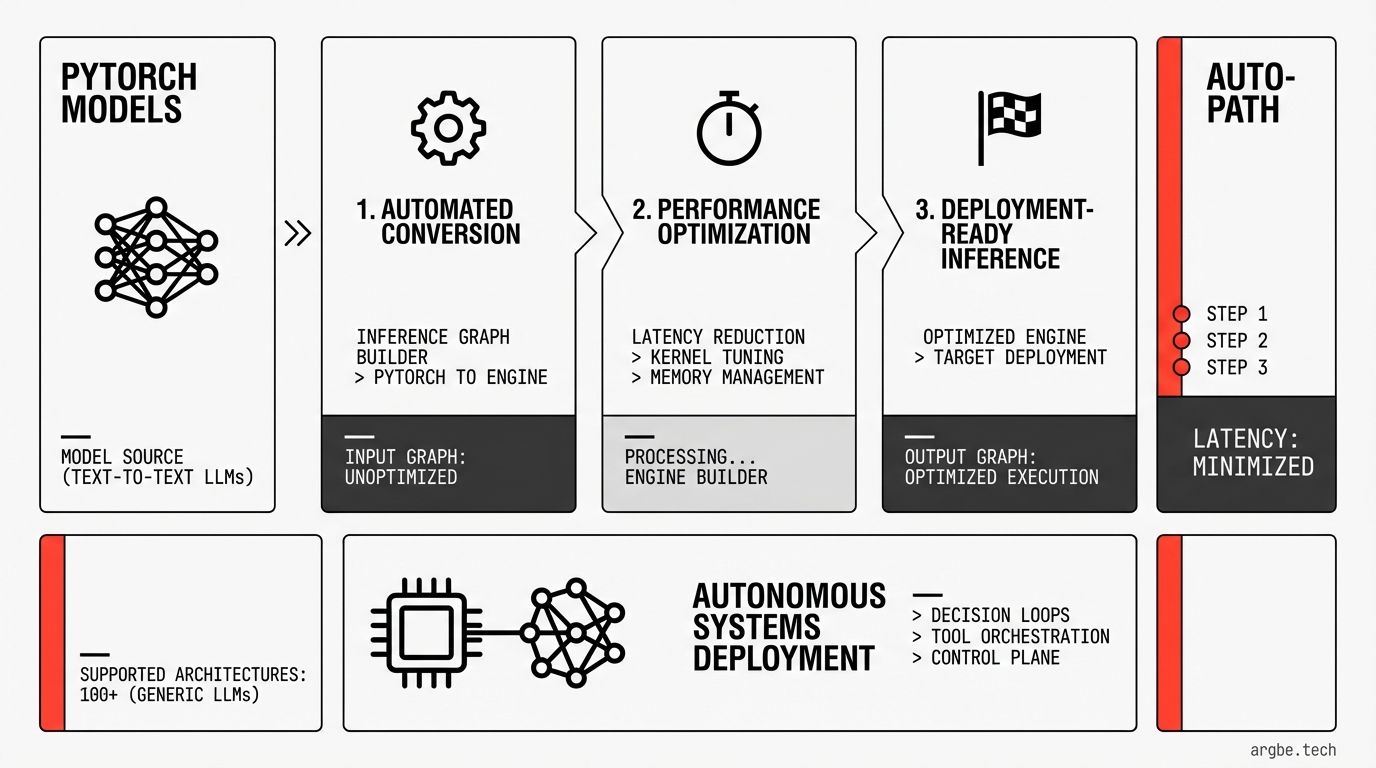
NVIDIA introduced TensorRT-LLM AutoDeploy (beta) to automate a three-step workflow—convert, optimize, and deploy—turning over 100 text-to-text LLMs into high-performance TensorRT-LLM inference graphs from their PyTorch sources.
The compiler-driven flow automates key inference tasks across single- and multi-GPU setups while keeping the PyTorch model as the system of record.
- Step 1 — Convert: compiles a PyTorch model into an inference-optimized graph without requiring manual code rewrites.
- Step 2 — Optimize: applies automated transformations such as quantization, attention fusion, and CUDA Graphs optimization for Hugging Face models.
- Step 3 — Deploy: handles runtime-critical details automatically, including KV cache management, weight sharding across GPUs, and operation fusion.
- Model coverage: supports immediate deployment for NVIDIA Nemotron models and more than 100 other text-to-text LLM architectures.
- Workflow design: keeps the original PyTorch model as the canonical source of truth for a unified training-to-inference path.