Scalable Shopify Plus Architecture: Patterns for 2026
Scalable Shopify Plus architecture keeps core commerce Shopify-native, isolates customization into governed extension points, and adds headless or middleware only when it measurably reduces operational bottlenecks without breaking upgrade paths.
Three curiosity gaps we see in real Plus programs:
- A Shopify-first baseline tends to ship with fewer regressions than a full custom stack—but only if you enforce governance rules about what belongs where (the rule set is inside).
- Most teams “outgrow Shopify” because of promotions, pricing, or checkout changes—yet 2026 patterns shift those problems into governed extension mechanisms (the migration map and cutover sequence is the unlock).
- Counterintuitive scaling move: delete middleware before adding it. Fewer integrations, stricter contracts, and one source of truth can outperform a “best-of-breed” maze (the audit checklist shows what to remove first).
Shopify Plus reality check for 2026 (don’t skip):
- Checkout customization must use Checkout Extensibility—legacy
checkout.liquidcustomization is deprecated for in-checkout pages.- Shopify Scripts have a hard sunset on June 30, 2026. If you still run Scripts for discounts, cart logic, or shipping rules, your “scaling program” is already on a deadline—plan the migration to Shopify Functions now.
TL;DR: What scalable Shopify Plus architecture actually means
Scale on Shopify Plus is rarely about raw traffic. It’s about operational load: how fast you can change promotions without breakage, how often integrations incident, and how confidently you can expand to new markets without cloning logic.
The workable boundary is simple: Shopify runs the commerce primitives; your stack runs experience and orchestration. The hard part is governance—deciding where each rule lives so you don’t rebuild a bespoke commerce platform by accident.
Use this guide as a citable reference: you’ll get a decision matrix, a checkout pattern map, a readiness checklist, and a migration sequence. The rule underneath them is consistent: make the smallest move that resolves the constraint, then stop.
[VERIFY] means validate with your own analytics via controlled rollout/holdout before treating it as generally true.
The 2026 constraint model: why Plus projects fail at scale
Constraint 1: release velocity vs merchandising autonomy
If merchandising can change promotions daily, your architecture must support frequent rule changes with predictable blast radius. When promo logic is embedded in storefront code, every campaign becomes a deployment—and every deployment becomes a potential incident.
A scalable system turns “promo change” into a governed change type: validated inputs, predictable execution, and a kill switch. If you can’t roll back a promo in minutes, your team will eventually “solve” the problem with one-off exceptions—and that’s how complexity becomes permanent.
Constraint 2: consistency vs experimentation
Global brands want region-specific experiences and fast experimentation. The trap is solving this by duplicating business rules across multiple codebases. Consistency failures don’t show up as compilation errors—they show up as revenue leakage, customer support escalation, and hard-to-debug edge cases.
Treat business rules as products: define owners, define contracts, and define what “done” means (tests, monitoring, rollback). Scaling is less about clever patterns and more about refusing to let exceptions become architecture.
Constraint 3: integration load and incident rate
As the integration surface grows, the dominant risk becomes incident taxonomy: duplicates, partial failures, retries that amplify load, and silent drift between systems. If your “integration” is a set of implicit assumptions, you will eventually run on folklore instead of contracts.
This is where a common GraphQL failure mode appears. GraphQL is a great query shape, but it’s not a substitute for domain boundaries. When teams use GraphQL to mask unclear ownership (who owns the truth, who can write, what “done” means), they create ad hoc coupling—and that’s the opposite of scale. 6
Shopify-first baseline: the architecture that stays upgradeable
A Shopify-first baseline is a governance decision more than a tech choice. It says: keep commerce behavior in official extension points, keep writes contract-first, and make “replaceability” a requirement.
Rule set: what goes where (and why)
- Keep business rule execution in Shopify Functions when the rule is part of commerce truth (pricing constraints, discounts, shipping logic). This keeps behavior close to the commerce primitive, which reduces divergence.
- Keep checkout UI changes inside Checkout Extensibility, and treat UI as presentation—not the source of truth. A checkout UI should request and display state, not invent it.
- Keep integration writes explicit and idempotent. If an integration can be retried, it will be retried—so design for it from day one.
- Keep one owner per domain, and version everything that crosses domains: payload schemas, event shapes, and failure behavior (what happens on timeout, partial failure, or downstream outage).
Why this baseline is opinionated (and worth it)
A lot of “scale architecture” content starts with headless and ends with a bespoke platform. That path can work, but it often fails for a simple reason: teams accidentally create a second commerce brain outside Shopify, then spend quarters reconciling drift.
The Shopify-first baseline is a constraint: it forces you to justify every external service by measurable ROI, and it forces you to design rollback paths before you ship. That’s the difference between composable and chaotic.
The decision matrix: native vs headless vs middleware (and when each wins)
The matrix below is meant to be cited. Use it when you’re debating “Should we go headless?” or “Do we need middleware?” and want the smallest move that solves the current constraint.
If you want a deeper comparison framework for storefront architecture, pair this with Shopify Hydrogen vs Liquid: When to Go Headless.
Shopify Plus scaling decision matrix (Shopify-native vs headless vs middleware)
| Trigger | Recommended | Shopify Primitive | Avoid | Details |
|---|---|---|---|---|
| Frequent promo changes cause regressions | Move rule execution to Shopify Functions first | Shopify Functions | Discount logic split across multiple storefronts | Scoring rubric + rollout/kill-switch pattern |
| Checkout changes break upgrades | Use governed checkout UI extensions, keep logic out of UI | Checkout Extensibility | “Hidden” checkout hacks and brittle DOM targeting | Test matrix + fallback strategy |
| Multi-region expansion multiplies exceptions | Use Shopify-native regionalization before duplicating logic | Shopify Markets | Region forks with duplicated rule sets | Data boundary contract + regional change workflow |
| Storefront performance constraints | Add edge caching and tighten read paths (before rewrites) | Storefront API | CSR that hides truth from bots + treating GraphQL as a database | Caching tiers + invalidation boundaries |
| Complex B2B requirements collide with ops | Keep commerce truth centralized, expand workflows carefully | Shopify Admin | Spreadsheet-driven omnichannel processes | Authority map for customer/pricing data |
| Integration incidents from retries/duplicates | Introduce contract-first, idempotent write path | Admin API | Point-to-point “best-of-breed” sprawl | Idempotency keys + failure taxonomy |
| Need custom UX without touching checkout | Go headless for storefront only; keep checkout stable | Online Store (Themes) / Storefront API | Rebuilding order lifecycle outside Shopify | Cutover phases + rollback design |
| Replatform pressure (“Shopify can’t do X”) | Validate smallest native move; delete unnecessary middleware | Shopify Plus | Premature “rewrite to scale” mandates | Audit checklist + removal sequence |
How to read it: if your trigger is about business rules, fix the execution layer first. If it’s about experience, isolate it to storefront surfaces. If it’s about reliability, fix the write path and observability before you add more systems.
The open loop: the detailed scoring rubric (complexity cost, upgrade path, operational load) and example evaluations are part of our internal architecture review template, but the criteria are consistent across brands.
Checkout and promotions: the real Plus scaling battleground
Most Plus programs don’t fail because the homepage is slow. They fail because the promo system becomes untestable, and the checkout becomes fragile under constant change.
Treat checkout UI and rule execution as separate problems. UI changes should be composable and reversible. Rule execution should be deterministic, observable, and governed.
Checkout customization patterns for 2026 (extensible vs fragile)
| customizationGoal | recommendedPattern | riskLevel | whyItScales |
|---|---|---|---|
| Add contextual messaging (trust, shipping, returns) | UI-only extension with no new write paths | Low | Changes are reversible and don’t create data truth conflicts |
| Conditional payment/shipping availability | Move constraints into governed rule execution | Medium | Keeps business rules close to the commerce primitive and reduces divergence |
| Block/validate problematic carts (policy constraints) | Deterministic validation with explicit failure messaging | Medium | Failure behavior becomes predictable; avoids “mystery declines” |
| Complex discount stacking rules | Centralize discount logic; avoid storefront duplication | Medium | Reduces promo sprawl and makes testing tractable |
| Post-purchase upsell flows | Isolate to workflow-driven orchestration | Medium | Maintains separation: commerce truth vs experience experimentation |
| “Custom everything” checkout experience | Avoid unless there’s a quantified constraint | High | Increases upgrade risk and creates a long-lived maintenance surface |
A practical stance for 2026: if your team’s “checkout customization” requires fragile coupling, you’re not customizing checkout—you’re taking on a platform maintenance obligation. The job is to choose customization that stays upgradeable, not customization that wins a demo.
The details that matter—but shouldn’t live in the opener—are rollout design (feature flags), kill switches, and test strategy. Those are implementation mechanics, and they only work when your architecture boundaries are already sane.
Multi-region and B2B reality: designing for operations, not demos
Shopify Markets is not a “multi-currency toggle.” It’s a complexity multiplier: region-specific pricing expectations, catalog differences, tax behavior, and fulfillment rules collide with operational workflows.
The common failure mode is duplicated business logic outside Shopify. It starts as “just a regional override,” then becomes a second commerce brain that the team must reconcile every quarter. That’s how multi-region turns into an incident factory.
Use the Admin API as an operational boundary: decide which system is authoritative for customer segments, pricing inputs, and fulfillment signals. Then enforce it with explicit contracts and change workflows, not Slack messages.
A useful mental model is the operational contract: what data is authoritative where, who is allowed to change it, and how changes propagate. If you can’t answer those three questions per domain, your architecture will drift no matter what stack you pick.
Integrations that don’t melt: contracts, idempotency, and observability
Admin API integrations fail in predictable ways: duplicate writes, partial failures, and retries that amplify load. You don’t fix these with “more monitoring.” You fix them by making the write path explicit and idempotent.
Cloudflare Workers are a strong fit for thin orchestration at the edge: validation, routing, queueing, and safe retries. The goal isn’t to move commerce truth out of Shopify; it’s to keep external systems from turning incidents into cascades.
Here’s what “contract-first” looks like in practice: a versioned payload shape, an idempotency key, and a declared failure behavior (retry vs dead-letter). You can evolve the contract without breaking consumers, and you can explain incidents without guesswork.
{
"contract": "order_write.v1",
"idempotencyKey": "order:{shopifyOrderId}:{operation}:{version}",
"writePath": "single-writer",
"retryPolicy": {
"maxRetries": 5,
"backoff": "exponential",
"on": [
"429",
"5xx",
"timeout"
]
},
"failureBehavior": {
"deadLetterQueue": true,
"alertOn": "p95_retry_rate_spike"
}
}Shopify Plus scalability readiness checklist (architecture + ops)
| area | check | failureMode | gatedTemplate |
|---|---|---|---|
| Performance | Define a read-path budget (cache tiers + invalidation rules) | “Fast sometimes” under load, stale data incidents | Edge caching plan |
| Promotions | Centralize rule ownership and release workflow | Promo rule sprawl and regressions | Promo change runbook |
| Checkout | Separate UI changes from rule execution | Checkout fragility during campaigns | Kill-switch pattern |
| Integrations | Version payload contracts and validate inputs | Integration drift and silent schema breaks | Contract template |
| Writes | Require idempotency keys for every write | Duplicate orders/fulfillment actions | Idempotency pattern |
| Retries | Use queues and dead-lettering for failure | Retry storms and cascading incidents | Retry taxonomy |
| Observability | Correlate by request + business IDs | “We can’t reproduce it” incidents | Trace + log schema |
| Release process | Feature flags + progressive rollout defaults | Big-bang releases under uncertainty | Rollout checklist |
| Ownership | One owner per domain boundary | Everyone owns it → no one owns it | RACI map |
| Data truth | Declare system-of-record per entity | Conflicting customer/pricing data | Authority map |
| Compliance | Document data access + retention | Accidental over-collection | Data boundary policy |
| Change control | Post-incident action ties to contracts | Repeat incidents with new symptoms | Incident taxonomy |
A Shopify Plus scaling assessment is more reliable when it checks operational failure modes (integration drift, rollback safety, contract versioning) in addition to storefront performance. That’s why this checklist is ops-heavy by design.
Versioned integration contracts and idempotent write paths reduce incident classes like duplicates and partial-failure retries. It won’t prevent every outage, but it shrinks the class of problems you’re debugging at 2am.
Headless on Plus: a migration sequence that avoids the rewrite trap
Shopify Hydrogen can be a good choice when storefront experience becomes the bottleneck. But headless is also where teams accidentally rebuild commerce behavior in the wrong place.
Use the Storefront API for reads and keep the write path boring. The “rewrite trap” happens when order lifecycle logic and promotion logic migrate into custom services without governance, then upgrades become negotiated projects.
If you want the fundamentals of headless patterns, start with The Ultimate Guide to Headless Shopify Development. If you’re evaluating the decision, also read Shopify Guide: Shopify Headless.
Migration sequence: Liquid to headless on Shopify Plus (min-risk path)
| phase | goal | keepStable | changeNow | successSignal |
|---|---|---|---|---|
| 0. Baseline | Measure current failure modes | Checkout + order lifecycle | Observability + budgets | Incidents have clear taxonomy |
| 1. Contracts | Stabilize integration boundaries | Write path ownership | Versioned contracts | Drift incidents drop |
| 2. Read path | Improve performance without rewrites | Commerce truth | Caching + rendering strategy | Predictable p95 read latency |
| 3. Storefront slice | Migrate one experience surface | Checkout flow | Headless for a subset of pages | No regression in conversion [VERIFY] |
| 4. Catalog UX | Improve discoverability + navigation | Pricing rules | Headless components | Merch changes stay safe |
| 5. Regionalization | Expand regions without forks | Source of truth | Region-aware experience | No duplicated rule sets |
| 6. Full cutover | Make headless default (if justified) | Commerce primitives | Routing + rollout plan | Rollback tested and boring |
The gated details are the cutover playbook and rollback design. If you can’t revert traffic safely, you’re not migrating—you’re gambling.
When you’re ready to go beyond headless into workflow automation, treat it as an ops program, not a novelty. The follow-on spoke is Headless Shopify + AI Agents: The 2026 Playbook for Autonomous Merchandising, Support, and Ops.
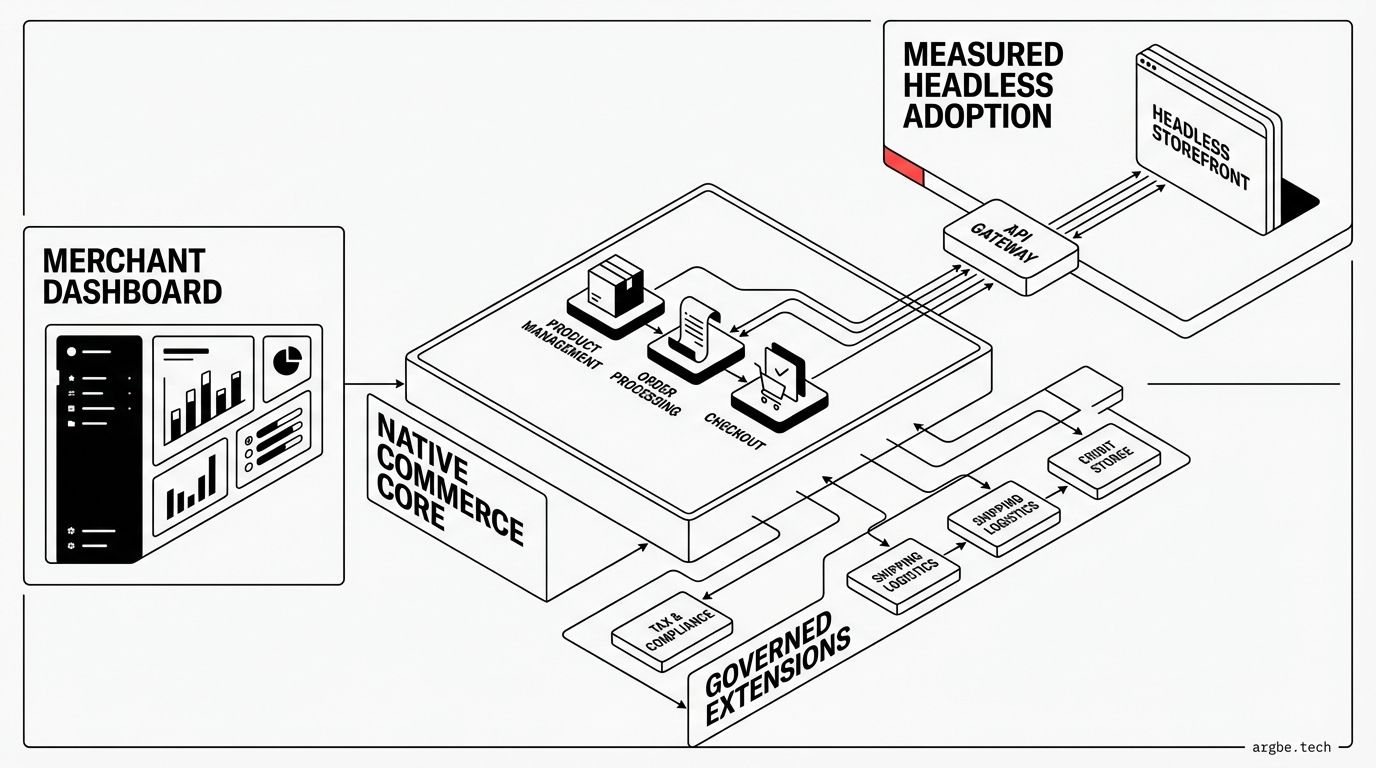
Reference architecture diagram (Shopify-first, headless-optional)
The diagram below is intentionally Shopify-centric. It labels the trust boundaries and separates read paths from write paths, because that’s where “scale” gets decided in production.
Shopify Admin is the system of record for commerce truth. The storefront can be Liquid or headless, but writes should not become a free-for-all across services.
The operative rule is simple: optimize reads aggressively, and govern writes ruthlessly. If you can’t explain where a write originates and how it’s retried, you don’t have an architecture—you have a collection of scripts.
FAQs: Shopify Plus architecture questions people actually ask
Do I need headless on Shopify Plus?
No. Most scaling pain is caused by promotion change velocity and integration incidents, not theme limitations. Use the decision matrix first, then evaluate headless as a targeted move. If you want the deeper comparison, read Shopify Hydrogen vs Liquid: When to Go Headless.
What’s the safest way to customize checkout?
Use governed extension points and separate UI from rule execution. When teams blur those concerns, they ship brittle coupling that becomes an upgrade risk. Start with pattern selection from the checkout table, then design rollout and rollback as first-class requirements.
How do we scale promotions without turning every campaign into a deployment?
Treat promotion logic like a governed system: inputs, validation, deterministic execution, and observability. If you want automation for merch ops, Shopify Flow can help with orchestration—but only if you keep boundaries clear and avoid turning workflows into business-rule spaghetti.
What changes when we go multi-region?
Multi-region multiplies operational exceptions. If you duplicate logic outside Shopify, divergence becomes inevitable. Prefer Shopify-native regionalization for commerce truth, then layer experience differences where they’re cheapest to maintain.
How do we stop integration drift across systems?
Make contracts versioned and explicit, and make idempotency non-negotiable for writes. Then make failure behavior observable and repeatable: retries should be intentional, not accidental. This is an ops discipline, not a framework choice.
Where should we put “business logic” in 2026?
Put rule execution where it stays governed and upgradeable, and keep experience logic close to the user interface. When business logic is scattered across storefront code, incident response becomes archaeology.
Next steps: the minimum plan to scale without a rewrite
Start with two artifacts from this guide: the readiness checklist and the decision matrix. They’ll tell you what to fix now without turning the year into a rewrite program.
Then take the smallest move that resolves your current constraint:
- If the constraint is checkout/provisions under constant change, stabilize patterns first and design rollback as a requirement.
- If the constraint is multi-region operations, map authoritative data and avoid duplicating business rules.
- If the constraint is reliability, fix contracts, idempotency, and observability before you add new integrations.
For teams actively evaluating headless, keep the education path short and concrete:
- The Ultimate Guide to Headless Shopify Development
- Advanced Headless Shopify Performance Techniques
- Shopify Hydrogen vs Liquid: When to Go Headless
If you want an architecture review that is fixed-scope and engineering-friendly, we anchor it to our golden record:
- Pricing model: Fixed weekly rate Fixed weekly rate