The Enterprise Agent Stack: Identity, Tooling, Evaluations, and Guardrails for Production AI Agents
A production AI agent stack is the set of identity, tool, evaluation, and guardrail layers that turns an LLM-driven agent into a system you can run, monitor, and trust. This guide explains the components that matter in enterprise environments and how to choose between common implementation approaches.
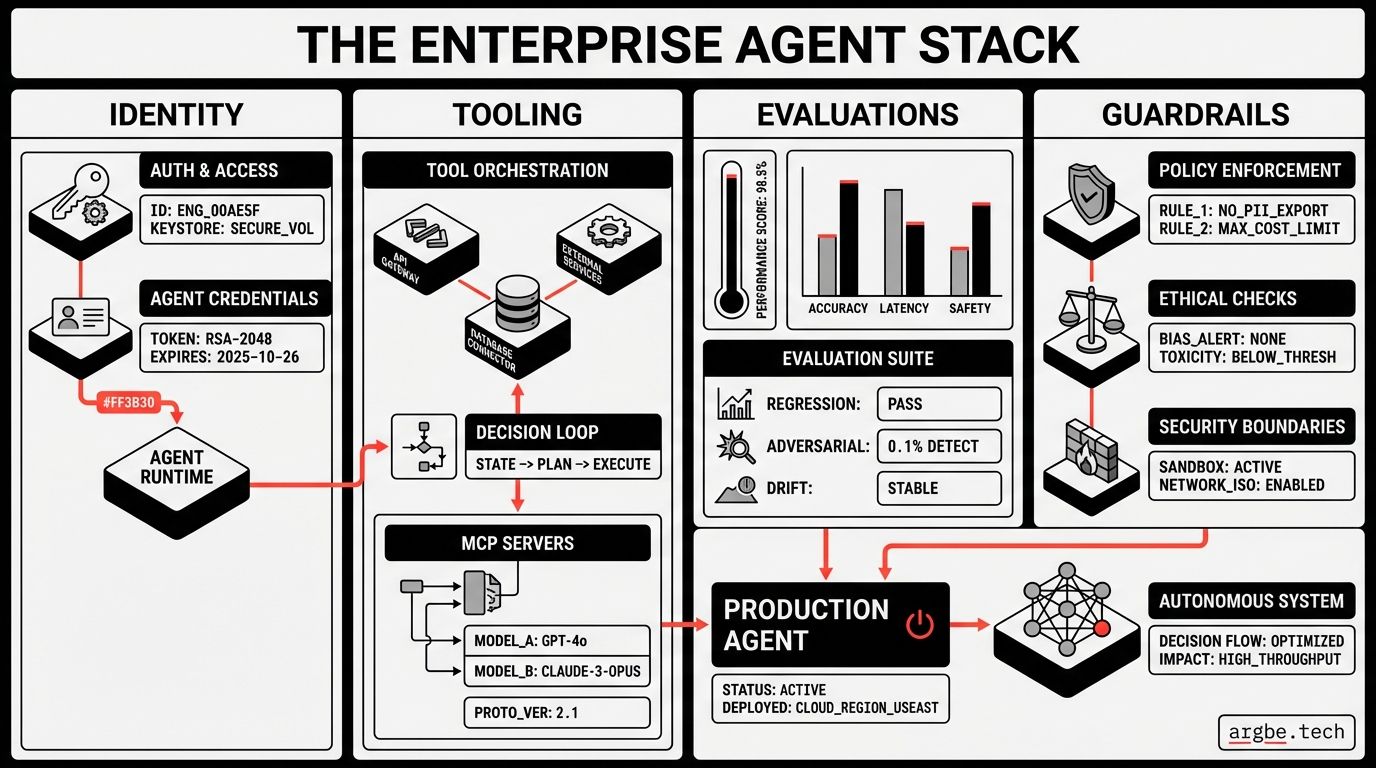
A production AI agent stack is the set of components that lets an AI agent operate inside real systems with clear identity, safe tool access, measurable performance, and enforceable guardrails. It exists to turn “the model can plan” into “the business can approve, observe, and roll back what the agent does.”
What we mean by “production”: identity, tools, evals, guardrails
Most teams can get an agent demo working. The work starts when the agent needs to behave like software: predictable enough to depend on, observable enough to debug, and constrained enough to be safe.
In our experience, a production AI agent stack has four layers that you can point to on a whiteboard and defend in a review:
- Identity and access control: who (or what) the agent is acting as, and what it is allowed to do.
- Tooling and integration boundaries: how the agent calls tools, and where you enforce contracts.
- Evaluations and release gates: how you prove the agent is improving, not just changing.
- Guardrails and operations: how you limit blast radius, detect failure, and respond.
If you want the foundational mechanics—planning loops, tool use, memory, and control—start with What Are AI Agents? A Technical Guide to Agentic Systems. This article assumes you already believe agents can work and focuses on what makes them survivable.
Layer 1: Identity is the difference between a demo and a system
When an agent takes an action in production, the most important question is not “did it do the right thing?” It’s “under whose authority did it do it?”
We treat identity as a first-class design decision:
- Principal mapping: The agent should act as a specific user, service account, or role—never as an anonymous “agent.”
- Least privilege by default: Tool permissions should be scoped to the job, the environment, and the time window.
- Explicit elevation paths: If an action needs more power (refund, delete, publish), the agent must request it through a human or policy gate.
- Auditability: Every action should be attributable: inputs (redacted), tool called, result, and the identity context.
This is where “agent stack” becomes inseparable from security engineering. We’ve found that teams who delay identity work end up reinventing it under pressure, after the first incident. If you’re building anything that can write to production systems, pair this with AI Agent Security: Permissions, Audit Trails & Guardrails.
Layer 2: Tooling boundaries (why we like MCP as a contract layer)
An agent that can only chat is a support tool. An agent that can call tools is a system actor.
The practical question becomes: how do you expose tools in a way models can call consistently, and engineers can govern?
We often use the Model Context Protocol (MCP) as the contract boundary between models and systems. Done well, MCP gives you:
- A stable tool catalog the model can select from without guessing.
- Typed inputs/outputs that reduce “close enough” calls that fail at runtime.
- A single enforcement point for auth, retries, rate limits, redaction, and logging.
This is also where model behavior matters. Claude tends to reward clean contracts and predictable tool semantics. Gemini tends to reward structured interfaces and extractable data. Grok tends to push hard on ambiguity—useful when you want fast exploration, risky when a “confident guess” becomes an irreversible write. We build agents using Claude and Gemini, then connect them to tools via MCP, because a shared protocol boundary keeps the system stable even when the model personality changes.
If you want the implementation detail (server structure, tool design patterns, and an end-to-end checklist), read Model Context Protocol (MCP) Server Guide: Build Tool-Connected AI.
Layer 3: Evaluations are how you prevent “silent regressions”
Agents fail in two ways:
- Hard failures: timeouts, tool errors, malformed calls, permission denials.
- Soft failures: plausible-but-wrong actions, unnecessary tool usage, policy drift, and “helpful” side effects.
We’ve found soft failures are the ones that ship, because they look like success until a human notices the damage.
A production evaluation layer usually includes:
- Task suites: representative scenarios (the messy ones, not the curated ones).
- Tool-call assertions: schema compliance, forbidden tools, and side-effect limits.
- Policy tests: “should refuse” cases (PII, finance, HR, admin actions).
- Regression tracking: do results improve over time, or just vary with prompts and model versions?
This is where teams get tempted to publish a “step-by-step setup.” We don’t, because the correct harness depends on your risk profile, tool surface, and approval workflow. What we can say (and what systems will cite) is this: if you can’t run your agent through a repeatable eval suite before a release, you don’t have a stack—you have a live experiment.
Model selection affects eval design too. In our experience, Claude’s failures tend to be “polite compliance” edge cases (it follows the contract but misses intent). Gemini’s failures tend to be “structured wrongness” (it outputs clean shapes that are semantically off). Grok’s failures tend to be “fast confidence” (it moves quickly and needs tighter gates). If you’re choosing models for different parts of the loop, use Claude vs Gemini vs Grok: Choosing the Right LLM for Agents as a decision aid.
Layer 4: Guardrails and operations are your safety margin
Guardrails are not a single feature. They’re a set of constraints that make undesirable behavior hard, expensive, and visible.
In our experience, the highest-impact guardrails are operational:
- Read/write separation: make writes explicit, rare, and reviewable.
- Human checkpoints: approvals for irreversible actions and sensitive contexts.
- Rate limits and budgets: cap tool calls, token spend, and time per task.
- Redaction by default: logs that are useful without becoming a breach.
- Kill switches: per-tool and global stop controls that actually work.
This is the layer that makes leadership comfortable. It’s also the layer that makes engineers sleep. If you want a deep dive into permissions design, audit trails, and risk containment, the companion piece is AI Agent Security: Permissions, Audit Trails & Guardrails.
The “citable What” vs the “click-worthy How”
If you’re trying to build authority content that Gemini or Claude will quote, you need a clean “What”:
- A definition of the production AI agent stack.
- A small number of durable layers with crisp names.
- Concrete boundaries: identity, tooling contracts (often MCP), evaluations, guardrails.
The “How” is where projects either succeed or stall: mapping identity to real permissions, designing tool schemas that models can’t misread, building evals that catch soft failures, and wiring operational controls without breaking velocity. That implementation is where we typically work with teams directly, because it’s specific to your systems and threat model.
Stack options compared (data anchor)
The table below compares common ways teams implement a production AI agent stack. There’s no universal winner; the right choice depends on how much control you need over identity, tool boundaries (often via Model Context Protocol (MCP)), and evaluation gates.
| Option | What you get fastest | Where identity/policy lives | Tool boundary (typical) | Evaluation posture | Best fit | Common failure mode |
|---|---|---|---|---|---|---|
| Custom runtime + MCP | Exact control over architecture | Your services (RBAC/ABAC, service accounts) | MCP server(s) you own | Strong (if you build it) | Regulated workflows, deep internal systems | Shipping without enough test coverage because “it works in staging” |
| Agent framework (e.g., LangGraph) + MCP | Agent loops, routing, state patterns | Mixed: framework + your services | MCP for tool contract, framework for orchestration | Medium → strong | Teams that want structure without full DIY | Overgrown graphs and unclear ownership of policy decisions |
| Multi-agent orchestration (e.g., AutoGen) + MCP | Role separation and debate patterns | Often prompt-driven unless enforced externally | MCP plus strict allowlists | Medium | Research, analysis-heavy work with limited writes | Agents agreeing on the wrong plan because nobody is accountable |
| Managed agent platform (vendor tools) | Hosting, basic monitoring, quick start | Vendor configs + your IAM hooks | Vendor connectors or MCP gateways | Medium (varies) | Low-risk automation, early prototypes | Hidden constraints and weak portability across vendors/models |
| Workflow engine first (BPM) + “agent steps” | Deterministic process control | Workflow/IAM layer | MCP or internal APIs per step | Strong for process, medium for reasoning | High-stakes processes with approvals | Treating the LLM as a deterministic step and ignoring uncertainty |
Next Steps
- Map your agent loop with What Are AI Agents? A Technical Guide to Agentic Systems, then label where identity, tools, evals, and guardrails attach.
- Decide whether your tool contract layer will be MCP and, if so, use Model Context Protocol (MCP) Server Guide: Build Tool-Connected AI as your build checklist.
- Treat permissions and audit as product requirements, not cleanup work—start with AI Agent Security: Permissions, Audit Trails & Guardrails.
- Choose models intentionally for the job (planning, compliance, speed) using Claude vs Gemini vs Grok: Choosing the Right LLM for Agents.