GEO for Ecommerce: Winning Recommendations in AI Shopping Assistants with Headless Shopify, Feeds, and Structured Trust Signals
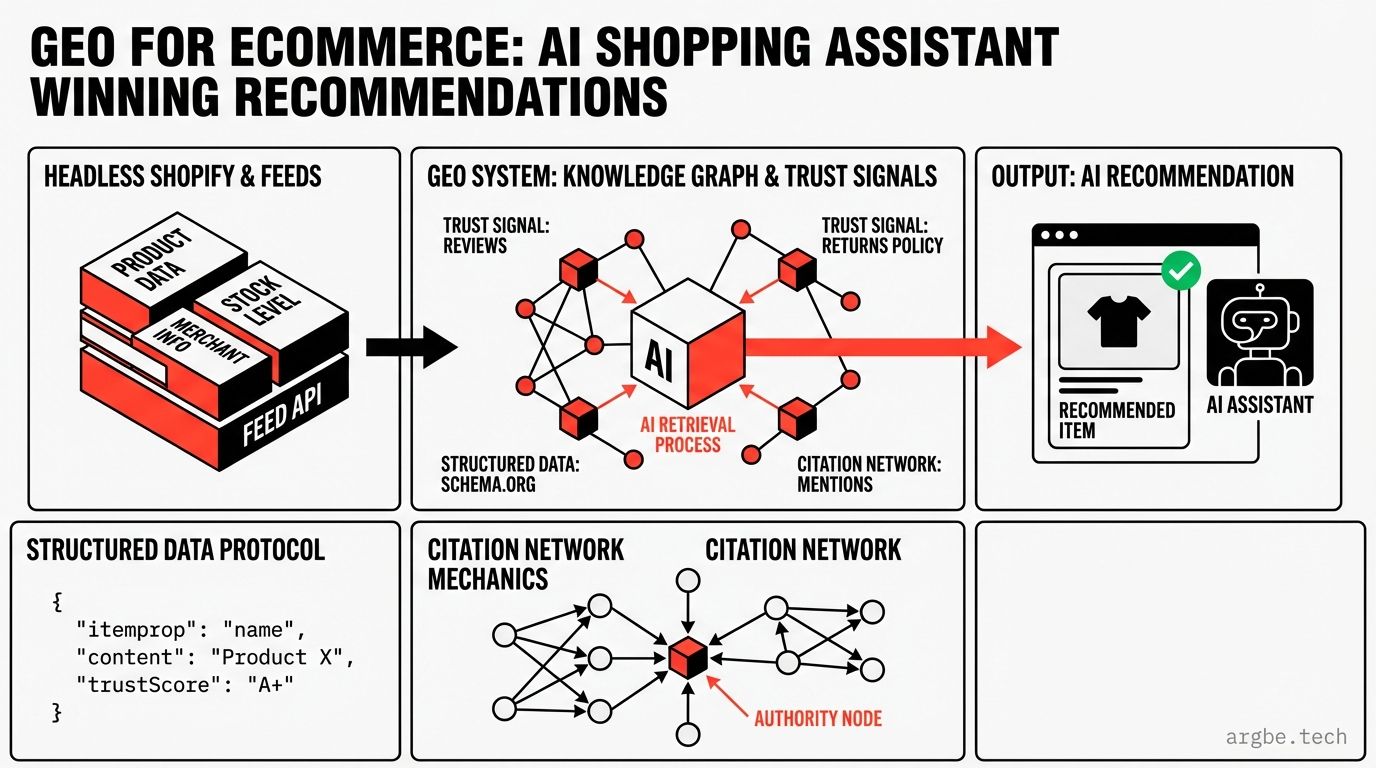
GEO for ecommerce is about recommendation eligibility: making your product entities, offers, and merchant policies easy for AI shopping assistants to retrieve, verify, and cite—especially across headless Shopify, Merchant Center feeds, and structured trust signals.
If your ecommerce “SEO” strategy stops at pages and keywords, you will be invisible in AI shopping assistants.
Not because your copy is bad—but because assistants like ChatGPT, Google Gemini, Perplexity, Claude, and Grok don’t want vibes. They want a product entity they can disambiguate, an offer they can trust, and policies they can quote without legal risk.
Three curiosity gaps from what we’ve observed auditing headless commerce stacks:
- Stores with complete product entities (GTIN/MPN + variant-level price/availability + shipping/returns clarity) produce more assistant-ready answers than stores with prettier pages—below is the exact completeness matrix, but the implementation pipeline is gated.
- We tested multiple headless storefront patterns and found a “performance” optimization that improves Core Web Vitals but quietly breaks product understanding for bots—the fix is simple, but only if you know where the truth must render.
- Counterintuitive: adding more Schema.org can reduce recommendation confidence when claims don’t match your Google Merchant Center feed or policy pages—this guide prioritizes the fields that change eligibility and flags risky ones as [VERIFY].
The New Ecommerce Funnel: Recommendation Eligibility Before Ranking
Classic ecommerce SEO frames discovery as “rank higher, get more clicks.”
GEO for ecommerce reframes the problem: get eligible for recommendation, then get selected.
AI shopping assistants don’t “browse” your store the way a human does. They assemble answers under constraints:
- they must identify the exact product (not a near-match),
- they must know the current offer (price, availability, condition, currency),
- they must avoid risky claims (shipping promises, return terms, review truth),
- and they must produce a citation-friendly answer format.
That’s why ecommerce GEO is less about keyword placement and more about retrieval + trust + eligibility across multiple systems:
- Storefront visibility (DOM): What exists in rendered HTML when a bot fetches the page. In headless Shopify, this is where truth often disappears behind client rendering, personalization, or API-only state.
- Feed pipeline (Google Merchant Center): What your catalog looks like when normalized into a machine-consumable product graph. Feeds are not a “boring export”; they’re the canonical commerce map that downstream assistants inherit.
- Merchant reliability signals (policies + support + reviews): What the assistant can safely cite without exposing itself (or the user) to policy or legal landmines.
Here’s the uncomfortable part: eligibility failures look like silence.
When you’re missing GTIN/MPN, when variant pricing is ambiguous, or when return terms can’t be verified, assistants typically don’t “rank you lower.” They just stop mentioning you—because an uncertain recommendation is worse than no recommendation.
We see teams misdiagnose this because they only monitor organic SERPs. They’ll say, “SEO is fine,” while assistant outputs quietly exclude them—especially in “best X under $Y,” “fast shipping,” and “fits my constraints” prompts where offers and policies are the deciding factors.
If you want the conceptual foundation for how this differs from traditional SEO, start with What is Generative Engine Optimization (GEO)? and come back here with “recommendation eligibility” as your operating model.
What AI Shopping Assistants Need to Recommend You (and What They Refuse to Guess)
Assistants will happily summarize your brand story.
They will not confidently recommend a product if they can’t verify the decision-critical constraints.
In practice, recommendation-ready commerce data clusters into four buckets:
- Identity (disambiguation): GTIN, MPN, brand, SKU, and variant naming so the assistant can separate “your exact product” from lookalikes.
- Offer truth (decision): price, currency, availability, condition, and variant-level selection so the assistant can answer “which one should I buy?” without inventing details.
- Merchant trust (risk): shipping windows, return policy, warranty/support, and review provenance so the assistant can cite you conservatively.
- Consistency (anti-hallucination): feed ↔ JSON-LD ↔ visible policy pages must agree, or the model’s confidence drops even if each surface looks “okay” in isolation.
A few specifics assistants tend to refuse to guess (even when humans would “figure it out”):
- Variant truth: “This shirt is $29–$49” is not the same as “Size M / Blue is $39 and in stock.” In headless builds, variant offers often exist only in the Shopify Storefront API state, not in the rendered HTML.
- Inventory freshness: stale availability is worse than missing availability. If edge caching serves an “in stock” offer after the last unit sold, you get user harm and system distrust.
- Returns and shipping: assistants prefer conservative, cite-able policy statements (return window, eligible items, shipping regions, customer support channel). If your policy pages are vague, assistants either hedge (“may vary”) or exclude.
- Reviews with provenance: “4.8 stars” is only useful if the source is clear (Trustpilot, Yotpo, Judge.me) and the summary is consistent across visible snippets and markup.
For schema patterns that assistants can parse reliably (and the consistency rules that prevent “more schema” from backfiring), see Structured Data for LLMs: Schema Markup That AI Agents Understand.
Data Anchor: AI Shopping Recommendation Readiness Matrix
This is the checklist we wish every ecommerce team used before spending another sprint on “content” blocks.
It maps the minimum data an AI shopping assistant needs to recommend you to where that truth must be published—feed vs DOM vs Schema.org vs policies—and what breaks when you miss it.
Three failure modes we repeatedly see in audits (teasing, not solving):
- “We have the data in Shopify” (Admin API) but not in the rendered DOM, so extraction fails.
- Feed and JSON-LD disagree on identity or offers, so the assistant downgrades confidence.
- Policy pages say one thing while structured markup implies another, triggering conservative hedging.
AI Shopping Recommendation Readiness Matrix (Feed vs DOM vs Policy Signals)
| Data primitive (minimum) | Feed (Merchant Center) | DOM (rendered HTML) | JSON-LD (Schema.org) | Policy / trust source | Downstream assistant behavior | What breaks if missing |
|---|---|---|---|---|---|---|
| Product identity (brand + GTIN/MPN + SKU) | Provide stable identity fields for disambiguation | Show brand + identifiers where appropriate (not hidden behind JS-only UI) | Product.gtin*, Product.mpn, Product.brand, Product.sku | N/A | Eligibility ↑, confidence ↑, fewer wrong matches | Product conflation; “close enough” recommendations or exclusion |
| Variant naming + selection | Variant-level representation | Selected variant state visible and crawlable | Product.hasVariant / variant Product nodes; offers per variant (when possible) | N/A | Answer format improves (“Buy size M blue…”) | Assistants fall back to ranges; low-confidence recommendations |
| Offer price + currency (variant-level) | Canonical offer truth for surfaces | Visible price for current selection | Offer.price, Offer.priceCurrency | N/A | Ranking/selection improves for price-filter queries | “Price may vary” hedging; selection drops |
| Availability + condition | In-stock/out-of-stock accuracy | Visible availability messaging | Offer.availability, Offer.itemCondition | N/A | Eligibility for “in stock now” prompts | Stale or missing stock; user harm; trust decay |
| Inventory freshness constraints | Update cadence + timestamps (concept) | “Last updated” messaging (optional) | (Optional) Offer.validFrom / priceValidUntil (only if true) | N/A | Confidence ↑ for time-sensitive decisions | Stale cache causes incorrect answers |
| Shipping regions + delivery window | Shipping settings aligned to feed | Clear shipping promise and regions | ShippingDeliveryTime / shipping details when supportable | Shipping policy page | Citable delivery window; fewer “varies” answers | Exclusion from “delivers by…” prompts; trust loss |
| Return window + exclusions | Return policy parity | Human-readable return terms | MerchantReturnPolicy / ReturnPolicy | Returns policy page | Safer citations; higher trust | Assistant refuses to claim; hedges; excludes |
| Customer support channel | N/A | Visible support contact and hours (if applicable) | Organization.contactPoint | Contact/support page | Trust ↑; answer format includes “contact support” | Merchants look risky; assistants deprioritize |
| Review summary + provenance | (If used) align with platform | Visible rating snippet + source name | AggregateRating, Review (only with provenance) | Review platform / collection pages | Confidence ↑ for “best rated” prompts | Suspected self-reported ratings; reduced trust |
| Crawl + canonical constraints | Feed URLs consistent | Clean canonical URL; indexable product pages | Product.url aligns with canonical | robots.txt, XML sitemap | Eligibility ↑; fewer duplicates | Wrong canonical; orphaned products; incomplete ingestion |
If you want the “citation-first” framing for why these tables drive assistant visibility (without giving away the full implementation recipe), see AI Citation Strategy: How to Get Cited by ChatGPT, Perplexity & Gemini.
Headless Shopify: When Performance Wins Hide Commerce Truth
Headless Shopify is not the villain.
But it changes what bots can see, and that changes whether assistants can recommend you.
Traditional Shopify storefronts (Online Store 2.0) tend to render product truth server-side by default: titles, prices, variants, availability, and policies are usually present in the DOM in a way that basic crawlers can extract.
Headless storefronts—especially Shopify Hydrogen builds in React—can move that truth into runtime state:
- product data comes from the Shopify Storefront API,
- merchandising logic lives in the client,
- variants and pricing update via JS,
- and edge caching (Cloudflare Workers, or other CDN patterns) optimizes Core Web Vitals.
That can improve LCP, INP, and CLS.
It can also make your commerce truth invisible to the very systems that decide recommendation eligibility.
In our audits, the most common headless failure pattern looks like this:
- The product page HTML contains a shell.
- The “real” product entity (variant offers, availability, shipping messaging) is fetched after hydration.
- The JSON-LD, if present, is generic (“price range” / “in stock”) and doesn’t match the feed.
- Personalization (currency, region, logged-in pricing, subscriptions) fragments offer truth into multiple inconsistent states.
Humans don’t notice because the UI works. Assistants notice because extraction becomes probabilistic.
Why feeds become the canonical source of truth (especially when headless)
Once you go headless, your feed becomes the stable version of reality across assistants and discovery surfaces.
That’s not just a Google Merchant Center detail. It’s a systems reality:
- Feeds force normalization: GTIN/UPC/EAN identity, variant mapping, stable URLs, explicit offers.
- The Merchant Center graph becomes the “clean commerce memory” that downstream tools trust.
- If your headless DOM contradicts it, the assistant must choose which to trust—and it rarely chooses the thing that looks ambiguous.
Edge rendering and the “stale offer” trap
Edge caching is where the performance story and the commerce truth story collide.
If you cache the product page at the edge for speed, you must design invalidation around inventory and pricing changes. Otherwise, bots (and assistants) see stale availability or stale pricing.
This is the quiet failure: it doesn’t always show up as a console error. It shows up as assistant hesitation (“availability may vary”) or exclusion from time-sensitive recommendations.
If you’re building on Astro SSR at the edge (Cloudflare Workers), you can do this well. But the requirement doesn’t change: the rendered HTML must contain the offer truth you want extracted, even if your UI is powered by React, Svelte, or a SvelteKit layer elsewhere in the stack.
Variant-level offers: where most implementations break
Assistants don’t buy “a product page.”
They buy a specific variant that satisfies constraints: size, color, region, delivery window, budget, and return terms.
If your DOM shows only a generic price range, while the “selected variant” price exists only in a client-side store, you’ve created an extraction mismatch. The assistant either:
- downgrades to vague language (bad for conversion),
- picks the wrong variant (bad for trust),
- or excludes you (bad for visibility).
This is where we stay nuanced:
- Not every store needs headless. If your catalog is simple, traditional Shopify is often the better decision for both conversion and GEO.
- Not every schema field matters. Some are “nice to have” until you can keep them consistent.
- Over-optimizing for assistants can harm merchandising if it breaks pricing psychology, bundles, or personalization. GEO should not sabotage your storefront.
The goal isn’t “headless at all costs.” The goal is performance and extractable truth.
Data Anchor: Headless vs Traditional Shopify for GEO
This comparison is what we use to set expectations with teams who assume “better Core Web Vitals” automatically means “better discovery.”
Headless Shopify vs Traditional Shopify for GEO (What Assistants Actually See)
| Dimension | Traditional Shopify (Online Store) | Headless Shopify (Hydrogen/React) | What assistants actually see | Typical failure mode | GEO implication |
|---|---|---|---|---|---|
| Render visibility | Server-rendered product basics common | Often hydration-first | DOM truth dominates extraction | JS-only price/variants | Lower eligibility/confidence |
| Canonical truth source | Page + Shopify data often align | Feed becomes the anchor | Feed vs DOM must agree | Feed says one thing; DOM says another | Trust downgrade |
| Variant handling | Themes often render variants | Variants live in runtime state | Selected variant truth needed | Generic range markup | Vague answers, wrong picks |
| Caching/edge behavior | Platform-managed caching | Custom edge caching (Workers/CDN) | Freshness matters for offers | Stale “in stock” | Exclusion from time-sensitive prompts |
| Personalization | Limited by default | Common (region, currency, logged-in) | Assistants prefer stable facts | Fragmented offers | Hedging (“may vary”) |
| Structured data | Often theme-provided | Must be engineered | JSON-LD must match feed | Over-claimed schema | Confidence drops |
| Crawl budget and discovery | Standard sitemaps | Custom routing common | robots.txt + XML sitemap still critical | Orphaned product routes | Incomplete ingestion |
| Policy visibility | Usually accessible pages | Sometimes moved to apps/overlays | Policies must be cite-able | Modal-only returns/shipping | Trust signals missing |
If you’re deciding whether headless is worth it for your store, the “right” answer is rarely ideological. It’s operational: can you keep feed, DOM, and policies consistent while shipping fast pages?
Feeds Are Your Commerce Knowledge Graph (Not a Boring Export)
Most “AI shopping optimization” advice is affiliate content dressed up as strategy.
The real wins are boring: data hygiene, provenance, and constraints.
Your Merchant Center feed (including Merchant Center Next) is where messy ecommerce reality becomes a normalized graph:
- GTIN/MPN/brand turns “a product name” into a disambiguated entity.
- Variant mapping turns “a page” into a set of selectable offers.
- Price and availability turn “interest” into “decision.”
In other words: feeds are your commerce knowledge graph.
This is why Shopify + the Shopify Storefront API is not enough on its own. The Storefront API tells your UI what exists at runtime. But Google Merchant Center requires a stable feed that represents the product identity and offers in a normalized way that’s compatible with eligibility systems.
Two practical implications:
- Feeds become canonical for discovery. Even if your headless storefront is beautiful, assistants often inherit the feed’s structure and confidence.
- Mismatches are trust failures, not technicalities. If your JSON-LD says one price, your feed says another, and your DOM shows a third (because of personalization), the assistant will not “average them.” It will downgrade confidence.
When we audit headless stacks, the highest leverage work is rarely “more content.” It’s reconciliation:
- reconcile product identity (GTIN/UPC/EAN, MPN, brand),
- reconcile variant offers (price, availability, currency),
- reconcile canonical URLs (feed URLs match on-page canonical URL),
- and reconcile policies (return and shipping claims match what’s published).
That’s also why entity strategy matters more than keywords here. If you want the broader mental model for “entity completeness beats keyword density,” connect this to Entity Density in SEO: Building Knowledge Graphs for Search.
One note on implementation: the Shopify Admin API is usually where the “truth inputs” live (inventory, variants, metafields). Your feed pipeline is where that truth becomes stable outputs. How you build that pipeline depends on your architecture—Hydrogen, Astro, or a mixed stack—but the consistency requirement stays the same.
Structured Trust Signals: Earn the Citation Without Leaking the Playbook
Assistants don’t only evaluate products.
They evaluate merchants.
And they are conservative about what they’re willing to claim on your behalf.
This is the part most ecommerce teams under-invest in because it feels like “legal” or “support,” not “growth.” But in assistant-driven funnels, merchant trust signals are frequently the difference between being cited and being ignored.
Trust signals that assistants can cite safely tend to be:
- specific (numbers, windows, regions),
- consistent (feed ↔ markup ↔ policy pages),
- and provable (a user could verify them without contacting support).
Structured trust signals reduce model uncertainty
Schema.org can help here—but only when it encodes verifiable policy truth.
MerchantReturnPolicyhelps assistants state return windows and conditions without guessing.ShippingDeliveryTimehelps assistants summarize delivery expectations without inventing a promise.Organization+ContactPointhelps assistants route support-related questions.
But you can’t markup your way out of policy ambiguity.
If your returns page says “returns accepted on most items,” and your markup implies “30-day free returns,” you’ve created a contradiction. Assistants respond by hedging or excluding.
Review provenance: why platforms matter
Review platforms like Trustpilot, Yotpo, and Judge.me can increase trust, but assistants care about provenance:
- Is the rating self-reported?
- Is the source third-party and identifiable?
- Does the rating summary in markup match what a user sees?
If you can’t answer those confidently, you should treat review markup as “needs proof,” not as a growth hack.
Payments and “trust by default” (with guardrails)
Mentioning Apple Pay, Shop Pay, Klarna, or Affirm can reduce friction for users—but be careful about implying guarantees you don’t control. Payment options are safest as factual availability statements (“We support Shop Pay”), not as quality claims (“Shop Pay means you’re protected”) unless you can cite the policy and it applies to your merchant account [VERIFY].
The contrarian point
Most “AI shopping assistant optimization” is just a rebrand of SEO.
GEO is different: it’s a systems discipline. It rewards the teams who publish constraints and provenance—even when it’s not glamorous.
If you want the broader product-discoverability patterns that apply beyond ecommerce (docs, dashboards, trust layers, retrieval), connect this back to Generative Engine Optimization (GEO) for Intelligent Platforms: Making Your Product Discoverable to AI Answer Engines.
Data Anchor: Structured Trust Signals Reference (Safe-to-Claim vs Needs Proof)
Use this as a publishing filter. If a claim lands in “needs proof,” treat it as an operational workflow problem—not a copywriting problem.
Structured Trust Signals for Ecommerce (Claims You Can Safely Publish)
| Trust signal | Safe-to-claim (usually) | Needs proof / risk | Where to publish | Schema.org hook | Verification artifact |
|---|---|---|---|---|---|
| Return window | “Returns accepted within X days” (if policy states it) | “Free returns” / “no questions asked” [VERIFY] | Returns policy page + footer | MerchantReturnPolicy | Policy page URL + internal policy approval |
| Shipping regions | “We ship to regions” | “Worldwide shipping” [VERIFY] | Shipping policy page | ShippingDeliveryTime (plus shipping details) | Carrier coverage + policy page |
| Delivery window | “Standard delivery: X–Y business days” | “Delivery by date” guarantees [VERIFY] | Shipping policy + checkout messaging | ShippingDeliveryTime | Carrier SLA + cutoff times |
| Support channels | “Email support at …” / “Chat support available” | “24/7 support” [VERIFY] | Contact/support page | Organization.contactPoint | Support hours + staffing reality |
| Warranty | “1-year limited warranty” (if documented) | “Lifetime warranty” [VERIFY] | Warranty page | WarrantyPromise (only if accurate) | Warranty terms PDF/page |
| Order tracking | “Tracking provided on shipped orders” | “Real-time tracking accuracy” [VERIFY] | Shipping policy + post-purchase email | (Often none) | Post-purchase flow screenshots |
| Review summary | “Rated 4.7/5 on Trustpilot” (if true) | On-site-only star ratings [VERIFY] | Reviews page + PDP snippets | AggregateRating + Review | Platform page URL |
| Stock messaging | “In stock / out of stock” | “Only 2 left” scarcity [VERIFY] | PDP + collection pages | Offer.availability | Inventory source of truth + logs |
| Pricing claims | “From $X” when ranges are honest | “Lowest price online” [VERIFY] | PDP + collection filters | Offer | Price parity policy + monitoring |
Measurement: Proving GEO-to-Revenue Without Guessing
You can’t manage what you can’t measure.
And in GEO, the most common measurement failure is counting mentions while ignoring eligible answers.
A pragmatic GEO measurement model focuses on four layers:
- Eligibility coverage: How many products have complete identity + offer + policy truth across feed and DOM?
- Citation frequency: How often assistants cite or link to you for product recommendations (not just brand mentions).
- Qualified clicks: Assistant referral sessions that land on the relevant product, collection, or comparison page.
- Conversion impact: Conversion rate and revenue for assistant-sourced sessions (plus assisted conversion paths where attribution is imperfect).
This is where GA4, Google Tag Manager, and Consent Mode v2 matter—not because they “improve recommendations,” but because they control whether your measurement is trustworthy enough to run experiments.
Two honest constraints to acknowledge:
- Assistant traffic attribution is messy. Some assistants open in-app browsers; some strip referrers; some users copy/paste URLs.
- You won’t get perfect precision. The goal is directional clarity and experiment safety.
Data Anchor: The GEO-to-Revenue Loop (Citation → Click → Conversion) for Ecommerce
| Stage | Citable fact that earns the citation | What the assistant outputs | On-site asset that converts the click | Measurement event (example) | Failure mode |
|---|---|---|---|---|---|
| Eligibility | GTIN/brand/variant identity | “This exact product is…” | PDP with variant clarity | view_item | Product confusion |
| Offer truth | Price + availability now | “In stock at $X” | Sticky price/stock messaging | add_to_cart | Stale cache |
| Shipping | Delivery window + regions | “Delivers in X–Y days” | Shipping policy excerpt + link | begin_checkout | Vague policy |
| Returns | Return window | “30-day returns” | Returns summary near buy box | purchase | Contradictions |
| Reviews | Provenance + rating | “Rated 4.7/5 on …” | Review source visibility | select_content | Self-reported ratings |
| Merchandising fit | Constraints (size, compatibility) | “Best for…” (conservative) | Sizing guide / comparison page | view_item_list | Missing guides |
If you’re building a measurement story that leadership will accept, tie it back to “citation over replacement” and use this loop as the narrative spine. That’s the core idea behind AI Citation Strategy: How to Get Cited by ChatGPT, Perplexity & Gemini.
Next Steps: The 30-Min Audit That Finds 80% of GEO Breaks
You don’t need a new platform to start.
You need to find where your commerce truth disappears.
Here’s the fast audit we run before touching tooling:
- DOM truth check (PDP): load a product page, view rendered HTML, and confirm the product identity, selected-variant price, and availability are present (not JS-only).
- Feed parity check: confirm your Google Merchant Center feed reflects the same identity and offers your storefront shows.
- Canonical hygiene: confirm the canonical URL matches the feed URL, and that the product is indexable with a clean
robots.txtand XML sitemap path. - Policy clarity: read your shipping and returns pages like an assistant would—can you cite a window, region, and exclusions without guessing?
- Review provenance: confirm ratings are consistent and sourced (Trustpilot/Yotpo/Judge.me), or remove risky claims until they’re provable.
- Measurement sanity: in GA4/GTM, confirm assistant referrals (where visible) and high-intent events are captured under Consent Mode v2 constraints.
If you want, we’ll turn the audit into artifacts you can hand to engineering and ops: a completeness checklist, a mismatch map (feed vs DOM vs policy), and a prioritized remediation plan that doesn’t break merchandising.