Structured Data for LLMs: Schema Markup That AI Agents Understand
Structured data helps LLM-driven products resolve what your page is about, which entities it references, and how to safely quote it. This guide explains what actually gets parsed, what gets ignored, and which markup patterns earn citations.
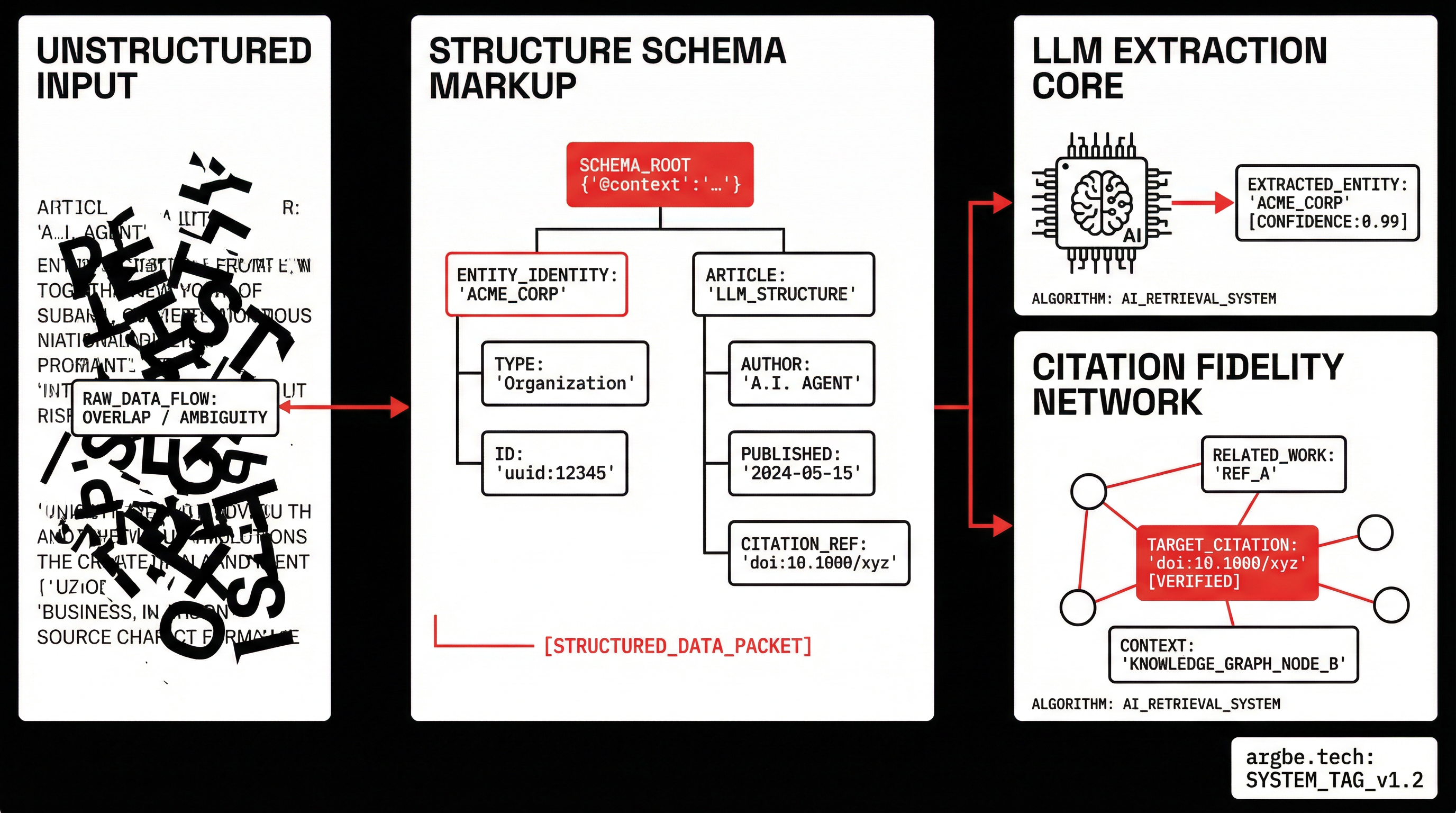
Structured data for LLMs is the practice of adding machine-readable meaning (usually Schema.org JSON-LD) so systems like Google, Gemini, ChatGPT, Perplexity, and Claude can resolve your entities, interpret page intent, and quote you with fewer assumptions.
Why “structured data” changes when the reader is an LLM
If you’ve been doing SEO for a while, you probably think of structured data as “the thing that earns rich results.” That’s still true for Google. But the moment an LLM is involved—whether it’s Gemini in Search, ChatGPT answering a query, or Perplexity stitching sources into a response—the success condition shifts from rendering a snippet to being correctly referenced.
In this guide, we treat “structured data llm” as shorthand for schema and page structure that reduce ambiguity for both crawlers and answer engines.
In our experience, the biggest GEO mistake is treating schema like decoration. For LLM systems, schema is closer to identity: it answers “Who is this?” and “What does this page represent?” in a way that survives summarization.
If you want the foundations first, start with What is Generative Engine Optimization (GEO)?. If you care about the outcome—being quoted—pair this article with AI Citation Strategy: How to Get Cited by ChatGPT, Perplexity & Gemini.
What LLM-driven products actually need from your markup
There’s a myth that “LLMs read everything.” In practice, LLM-based experiences are layered:
- Retrieval finds candidate pages (classic search signals still matter).
- Extraction pulls candidate facts (headings, tables, definitions, lists, and sometimes structured data).
- Reasoning stitches the answer and decides what to cite.
Structured data mainly helps in the middle layer. We’ve found it reduces ambiguity in two places that routinely break citations:
- Entity resolution: Are you a company, a product, a person, or a template site?
- Attribution: If a model quotes a definition, does it “know” who said it and where it came from?
That’s why Schema.org is still the workhorse. It gives Google a consistent parse path, and it gives downstream systems (including LLM-backed ones) a cleaner way to identify what the page is and which named things it contains.
If you’re also working on knowledge graph signals, read Entity Density in SEO: Building Knowledge Graphs for Search. Entity clarity and schema work best as a pair, not as separate checklists.
The schema patterns we see cited (and the ones we see ignored)
We’re not trying to “trick” ChatGPT, Perplexity, Claude, or Gemini. We’re trying to make it easy for their pipelines to avoid mistakes.
Here’s what tends to work reliably:
- Organization + WebSite + WebPage as your baseline identity layer.
- BreadcrumbList when the page lives inside a clear hierarchy (useful for topical clusters).
- Article (or a more specific subtype) when you publish guidance that should be attributed.
- FAQPage only when the questions are truly on-page and answered clearly (LLMs love explicit Q→A structure).
Here’s what we routinely see misused:
- Overstuffed markup that repeats the same keywords across fields. It reads like spam to humans, and it often confuses parsers.
- Mismatched types (e.g., marking a service page as an Article) that create conflicting interpretations.
- Markup without text support—schema claims that aren’t backed by visible page content.
The pragmatic rule we use: If a human can’t point to the sentence that makes the schema true, the schema is risky.
A citable “What” that stays stable across tools
If your goal is citations, the “What” you publish needs to be extractable without a long chain of interpretation. This is where the Direct Answer block and the table below matter: they give systems something to lift cleanly.
We usually structure the core of an authority page around:
- A definition (one paragraph) that can be quoted verbatim.
- A small set of claims that are checkable (“X is used for Y; Z is not meant for…”).
- A comparison table that turns nuance into discrete choices.
We keep the deeper implementation detail (our audit checklist, validation workflow, and templates) as the “How.” That’s not stinginess—it’s how you earn click-through instead of getting fully summarized.
Comparison: structured data options for LLM-facing visibility
| Option | Best for | Who reliably consumes it | Strengths | Limitations | Effort |
|---|---|---|---|---|---|
| Schema.org JSON-LD (Organization, WebSite, WebPage, Article, FAQPage) | Entity identity + citation-ready extraction | Google (Search), Gemini-driven experiences; sometimes helpful context for other systems | Explicit meaning, stable identifiers, clean attribution | Requires correctness; bad schema can add ambiguity | Medium |
| Open Graph / Twitter Cards | Preview accuracy when links get shared | Social platforms; some LLM products use previews as lightweight hints | Simple, improves title/description consistency | Not a substitute for schema; limited semantics | Low |
| XML Sitemap + RSS/Atom | Discoverability + crawl scheduling | Google and traditional crawlers; also useful for downstream indexers | Clear inventory of URLs, update signals | Doesn’t explain meaning of content | Low |
llms.txt (curated agent-facing index) | Steering an agent to the right pages | Emerging: tooling ecosystems and some agent workflows | High signal-to-noise, reduces “wrong page” retrieval | Not a standard; adoption varies | Low–Medium |
| Well-structured HTML (headings, definitions, tables) | Extraction quality | Everyone: Google, Gemini, ChatGPT, Perplexity, Claude | Models extract tables/definitions well; no special syntax | Requires editorial discipline; not “metadata” | Medium |
Implementation checklist (the parts we’d never skip)
In our audits, the pages that earn consistent citations tend to share the same boring fundamentals:
- One canonical URL, consistent across HTML, schema, and internal links
- A single, unambiguous primary entity (your Organization, product, or service)
- A definition block that can stand alone without surrounding context
- Tables that don’t require interpretation to be useful
- Schema that matches what the user can see on the page
If you want the full version of our structured data checklist (including validation tooling, error patterns we see in production, and how we map schema to cluster strategy), that’s the part we normally walk through with clients. Get in touch and we’ll point you at the right approach for your stack.
Next Steps
- If you’re building the cluster: read What is Generative Engine Optimization (GEO)? and define your pillar/spoke map first.
- If you’re optimizing for attribution: apply AI Citation Strategy: How to Get Cited by ChatGPT, Perplexity & Gemini before you obsess over markup details.
- If you’re strengthening entity signals: pair this with Entity Density in SEO: Building Knowledge Graphs for Search and tighten your on-page entity language.