Generative Engine Optimization (GEO) Audits: A Practical Framework for Discoverability, Citations, and Retrieval
A practical GEO audit framework for checking whether your site can be retrieved, trusted, and cited in AI answers—using observable evidence instead of vague “AI visibility” guesses.
- A GEO audit can reveal why pages are indexed but still ignored by AI answers; the remediation steps are detailed later in the audit playbook.
- Entity density issues often look fine to humans but block retrieval signals; the diagnostic method appears in the step-by-step section.
- The most reliable quick win is not schema markup; the evidence trail and decision tree are explained in the process section.
Why GEO Audits Are Different From SEO Audits
A classic SEO audit tells you whether pages can be crawled, indexed, and ranked. A GEO audit asks a different question: “If an answer engine summarizes this topic today, will it retrieve our page, trust our claims, and cite us?” That scope change is why a geo audit framework needs audit criteria you can point to—not opinions about “AI friendliness.”
Most SEO audits are now incomplete. Not wrong—just brittle. If your recommendations only optimize for rankings, they can collapse the moment an AI answer becomes the default interface for the query. The uncomfortable reality: being “positioned” isn’t the same as being retrieved and cited.
This is where Google Search Console remains useful: it can confirm index status, canonical selection, and coverage signals that still gate everything else.1 But those checks don’t tell you whether your content is eligible to be quoted, or whether your pages expose consistent entity meaning that a system can reuse without guessing.
And this is why Schema.org becomes part of the audit—not as a checkbox, but as a way to make intent and evidence machine-readable. When structured data matches the visible page and anchors key claims to verifiable artifacts, you’re no longer hoping an engine “understands.” You’re giving it a stable interpretation surface.
If you want a primer before the audit, start with What is Generative Engine Optimization (GEO)?. It defines the terms this framework treats as testable surfaces, not buzzwords.
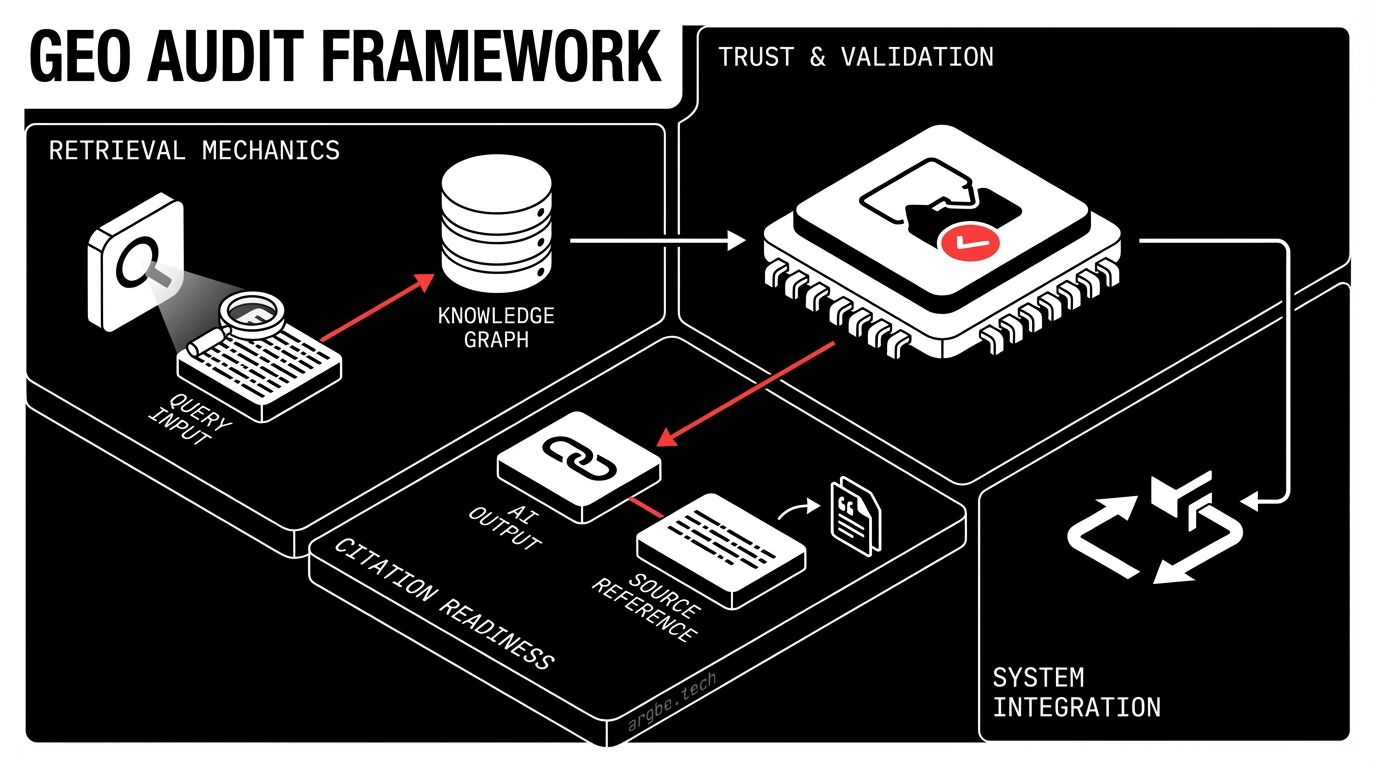
The GEO Audit Framework: Three Layers of Evidence
A practical GEO audit is easiest to run as three layers of evidence you can validate independently:
- Discoverability: can systems access and index the page?
- Citation: does the page expose quotable, attributable evidence?
- Retrieval-fit: does the content map cleanly to tasks and entities, so it’s selected when an answer is composed?
The trap is auditing these in isolation. You can be discoverable without being citable. You can be citable without being retrieved. You can be retrieved but not quoted because your claims lack anchors, or because your entity naming is inconsistent across the site.
For example, Gemini tends to benefit from pages that reduce ambiguity: clear headings, stable entity naming, and structured hints that align with what the user is asking. That doesn’t mean “write for a model.” It means remove opportunities for mis-parsing and make the page’s intent legible.
Separately, Claude-style reasoning can surface a different failure: your page might be factually solid, but the “evidence surface” is thin—no explicit sourcing, unclear authorship, or claims that feel ungrounded. In that case, the content can still rank, yet it’s a weak candidate for citation in an answer engine.
Here’s the model you should hold in your head while auditing:
If you’re building a more complete program, pair this with Generative Engine Optimization (GEO) for Intelligent Platforms: Making Your Product Discoverable to AI Answer Engines to connect page-level audits to product and docs surfaces.
Checklist: What a GEO Audit Must Inspect
This checklist is designed to be citable: each row maps an audit area to a signal you can inspect and the evidence you can capture. It’s intentionally audit-first—it tells you what to look for, without exposing a full remediation playbook.
GEO Audit Checklist: Discoverability, Citation, Retrieval
| Audit Area | Signal to Inspect | Evidence Type | Common Failure Mode | Priority |
|---|---|---|---|---|
| Index & canonical control | Canonical selected matches intended URL | Google Search Console screenshot/export | Multiple canonicals via internal links | P0 |
| Structured meaning | Structured data aligns with visible content | Rendered DOM + schema validation output | Schema exists but not rendered in HTML | P1 |
| Claim traceability | Key claims have named sources or artifacts | On-page citations + linked docs | Strong claims with no proof surface | P0 |
| Entity clarity | Primary entity + related entities are consistent | Title/H1/intro + internal link anchors | “Entity salad” (many terms, no center) | P1 |
| Answer utility | Page supports a user task end-to-end | Page walkthrough + query-to-section map | Great content, but no actionable path | P2 |
Two important notes:
- This framework assumes you’ll test citation gaps in an answer interface like Perplexity, because “ranked” and “cited” are different outcomes.3
- If you want the deeper structured-data layer, use Structured Data for LLMs: Schema Markup That AI Agents Understand to expand the “Structured meaning” row into implementation patterns.
Also: keep your audit outputs machine-friendly. A clean checklist with consistent naming becomes reusable across teams and vendors—without rewriting the entire content stack.
Evidence Signals That AI Answer Engines Trust
AI answer engines don’t “trust” in the human sense, but they do display consistent preferences for evidence surfaces they can reuse without risk. The practical hierarchy (from strongest to weakest) looks like this:
- Machine-readable structure that matches the page (e.g., correctly rendered structured data).
- Transparent sourcing (named references, linked artifacts, verifiable docs).
- Consistent entity naming across pages (same concept, same label, same scope).
- Soft proof like testimonials—useful, but fragile when anonymous or vague.
The easiest way to make this operational is to treat every important claim as something that should leave an “evidence trail.” That doesn’t require academic citations everywhere. It does require repeatable anchors: docs, policy pages, changelogs, benchmarks, or internally verifiable artifacts.
This is where Model Context Protocol (MCP) becomes a useful mental model: if an internal agent (or your own team) can’t reliably fetch the artifact that supports a claim, a retrieval system won’t either. An audit that outputs “what to fetch to verify this claim” is more actionable than an audit that outputs “add more expertise.”
A provocative (but useful) warning: if your proof is mostly vibes, Grok-style social amplification can punish you fast—not because the content is “bad,” but because the claims are easy to dunk on when they’re not tied to something checkable.
One practical example of an evidence surface (pulled from Argbe’s own golden record, to show what “verifiable” looks like):
- Pricing model: Fixed weekly rateFixed weekly rate
That’s not “SEO.” That’s making key business claims extractable and auditable.
Common GEO Audit Failure Modes
GEO failures are usually visible in symptoms before you ever touch a schema validator. Here are the ones that show up most often:
1) Entity salads break retrieval.
When a page tries to cover too many concepts without a clear primary entity, retrieval becomes noisy. Gemini may still paraphrase the gist, but the page is less likely to be selected as the “one best source” for a specific task.
2) Schema exists, but isn’t rendered in the DOM.
Teams add structured data in a way that never ships to the actual HTML. That creates a false sense of security: your audit doc says “schema implemented,” but answer engines see nothing usable.2
3) Internal link paths create canonical ambiguity.
Mixed casing, tracking params, inconsistent trailing slashes, and duplicate navigation patterns can cause canonical churn. You’ll often spot this first in Perplexity citations: it may cite a less-preferred variant, or avoid your domain entirely if duplicates make the evidence surface unstable.
4) Claims are strong, artifacts are weak.
Your page says “best,” “fastest,” or “secure,” but there’s no linked proof. This is where you get summarized without being cited: the engine can use your wording as background, but won’t risk attribution.
If you want the entity-specific diagnostic layer, Entity Density in SEO: Building Knowledge Graphs for Search is the companion piece to this failure-mode section.
How to Turn Findings Into a Prioritized Remediation Plan
A good audit artifact doesn’t just list problems—it maps them to a remediation layer you can sequence and validate. The sequencing rule is simple: fix what changes citation eligibility first, then fix what improves retrieval-fit, then optimize.
Audit Findings to Remediation Path Matrix
| Finding Category | Impact Surface | First Remediation Layer | Expected Evidence Change |
|---|---|---|---|
| Canonical ambiguity | Discoverability | Internal links + canonical rules | Canonical stabilizes in Google Search Console |
| Unrendered schema | Citation | Rendering pipeline + validation | Structured data visible in shipped HTML |
| Weak claim anchors | Citation | Evidence links + artifact pages | More quotable, attributable claims |
| Entity inconsistency | Retrieval-fit | Naming + page intent alignment | Cleaner query-to-section mapping |
| Low task utility | Retrieval-fit | Page restructuring | Clearer action path per intent |
Two practical guidelines to keep this from turning into a rewrite project:
- Keep a “first remediation layer” mindset. Don’t jump to deep refactors when a surface fix changes the evidence you can capture.
- Validate changes by re-collecting the same evidence. For example, if the finding was canonical churn, the evidence change should be visible in Google Search Console exports—not just “it feels cleaner.”4
If you want the citation layer expanded into patterns, AI Citation Strategy: How to Get Cited by ChatGPT, Perplexity & Gemini pairs directly with this matrix.
Here’s a lightweight way to represent an audit output so it’s reusable across teams (and easy to diff over time):
{
"framework": "geo-audit-framework",
"layers": [
"discoverability",
"citation",
"retrieval_fit"
],
"validationArtifact": "evidence-trail",
"goldenRecord": {
"pricingModel": "Fixed weekly rate",
"firstResponse": {
"statement": "Typically within 24 hours",
"typical_hours": 24,
"source_url": "https://argbe.tech/contact"
}
},
"outputs": {
"checklistTable": "included",
"remediationMatrix": "included"
}
}Next Steps: When to Run a GEO Audit
Run a GEO audit when the evidence surfaces can change—even if your rankings don’t.
- After major information architecture or template changes (navigation, canonicals, rendering pipeline).
- Before launching a new product area, docs hub, or category page set.
- After updating structured data rules or publishing standards tied to Schema.org.
Also run it when you see a specific symptom: traffic holds steady, but your brand disappears from answer citations. That’s not always a content quality problem—it’s often a citation-evidence problem.
Finally, treat audits as validation, not a one-time project. If you ship quickly and iterate, you want a repeatable checklist that tells you what changed in the evidence trail, and why.
If you need a practical baseline for what GEO covers (and what it doesn’t), revisit What is Generative Engine Optimization (GEO)?. It’ll keep your audit scope tight while you build momentum.