Schema-First GEO for Ecommerce: Product Knowledge Graphs, Merchant Feeds, and LLM-Ready Structured Content
Ecommerce knowledge graph SEO turns a product catalog into a set of resolvable entities and relationships, so search engines and answer engines can retrieve correct facts and cite you with confidence. This guide explains what to model, what to publish, and which structured channel to prioritize first.
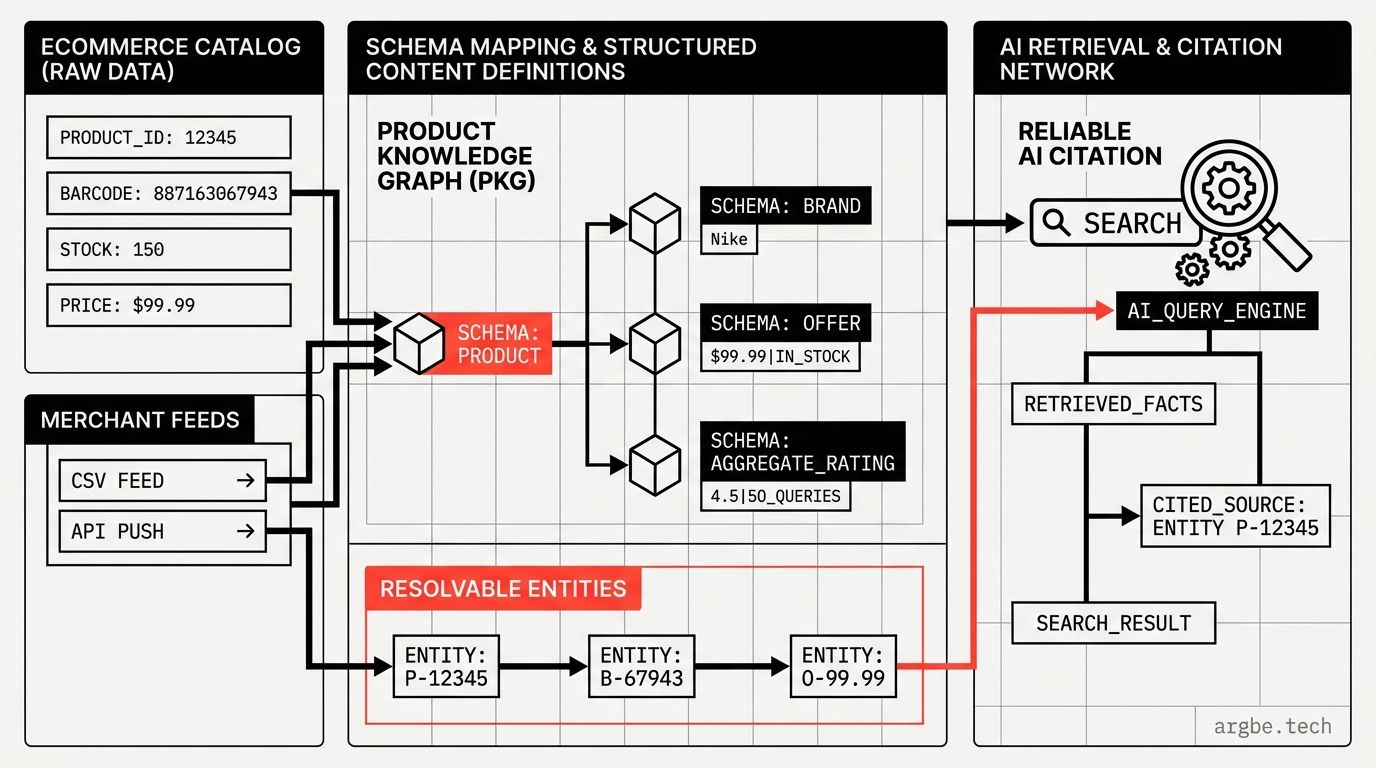
Ecommerce knowledge graph SEO is the practice of turning your product catalog into a machine-readable set of entities (products, offers, brands, categories, locations) and relationships so systems like Google, Gemini, ChatGPT, Perplexity, and Claude can retrieve the right facts and attribute them to you instead of guessing.
Why “SEO for ecommerce” is now a data architecture problem
Classic ecommerce SEO taught teams to think in URLs: category pages, PDPs, faceted navigation, and internal links. That still matters. But when the reader is an answer engine, the unit of meaning shifts from “a page” to “a product entity with stable identifiers and consistent attributes.”
In our experience, the biggest ecommerce visibility failures happen when the site is technically crawlable, but the catalog is not interpretable:
- A SKU has three names across feeds, PDPs, and support docs.
- Availability and pricing differ between the store, the feed, and the checkout.
- Variant relationships are implicit (color/size) but never stated cleanly.
- Brand and model identifiers are missing or treated as “marketing copy.”
A product knowledge graph is the cleanest mental model for fixing this because it forces a single question: What are the entities, and how do they connect? If you want the broader frame for this, start with What is Generative Engine Optimization (GEO)?.
What a product knowledge graph is (and what it is not)
When we say “knowledge graph” in ecommerce, we’re not talking about a fancy visualization or a one-off SEO project. We mean a canonical representation of catalog truth:
- Entities: Product, Offer, Brand, Category, Collection, Store/Location, Review, Specification
- Identifiers: SKU, GTIN, MPN, brand + model, internal IDs, canonical URLs
- Relationships: “isVariantOf,” “belongsToCategory,” “isSoldAt,” “hasOffer,” “compatibleWith,” “accessoryFor”
It’s not a replacement for good pages. It’s the structure that keeps pages, feeds, ads, and agents consistent.
If you’re new to entity thinking, Entity Density in SEO: Building Knowledge Graphs for Search explains why named entities and clear relationships change how systems interpret your site.
The GEO angle: optimize for citation, not replacement
If you publish ecommerce content that’s easy to lift, AI systems will lift it. That’s not a moral judgment; it’s the behavior of retrieval + extraction pipelines. Our goal in GEO is to make the “What” citable and keep the “How” intentionally procedural so the click still matters.
Here’s the pattern we use:
- Publish the “What” as stable facts: definitions, tables, explicit attribute lists, and unambiguous entity naming.
- Keep the “How” as your playbook: normalization rules, QA gates, feed validation workflow, and your exact mapping between PIM fields and schema properties.
That strategy aligns with both human decision-makers and answer engines. It also pairs well with AI Citation Strategy: How to Get Cited by ChatGPT, Perplexity & Gemini, where we go deeper on what tends to get quoted.
Merchant feeds vs on-site schema vs “the graph”: where teams get stuck
Most ecommerce teams already have “structured data,” but it’s fragmented:
- Merchant feeds are optimized for shopping surfaces and ads.
- On-page schema is optimized for page interpretation and rich result eligibility.
- The internal catalog model (PIM/ERP) is optimized for operations.
GEO is the discipline of making these three views agree on identity and attributes.
In our audits, the fastest path to better attribution is usually not “add more schema.” It’s:
- Pick one canonical identifier strategy (SKU + GTIN/MPN where possible).
- Make your primary entity naming consistent across PDP, feed, and support docs.
- Publish a small number of high-signal fields everywhere (brand, model, variant, price, availability, canonical URL).
This is also where structured content matters as much as markup. Even if your JSON-LD is perfect, systems still extract heavily from headings, definitions, and tables. If you want the editorial side of the stack, read Structured Data for LLMs: Schema Markup That AI Agents Understand.
The agent reality: your catalog will be queried, not browsed
When someone asks “Which 16-inch carry-on fits European airline rules and has a laptop sleeve?” they don’t want to browse 40 PDPs. They want an answer.
We build AI agents using Claude and Gemini, then connect them to tools via MCP so they can query catalogs, check inventory, and return answers with sources. When we test those agents against ecommerce sites, the same bottleneck shows up: the agent can only be as precise as the site’s entity model and published attributes.
That’s why a knowledge graph is more than “SEO.” It’s future-proofing for every interface that asks your catalog questions—Google surfaces, internal search, customer support, and the LLM layer.
If your product is itself an intelligent platform (or you sell into one), Generative Engine Optimization (GEO) for Intelligent Platforms: Making Your Product Discoverable to AI Answer Engines is the companion piece.
Comparison: ecommerce knowledge graph channels (what each one is actually for)
This table is the citable “What”: which structured channel to prioritize based on outcomes and who is parsing it.
| Option | Best for | Who reliably consumes it | Strengths | Limitations | Effort |
|---|---|---|---|---|---|
| Google Merchant Center product feed (incl. supplemental feeds) | Shopping visibility + structured inventory | Google (Merchant Center/Shopping) and adjacent product surfaces | Strict attributes; fast feedback; forces catalog discipline | Can “pass” while still disagreeing with PDP identity (titles, identifiers, landing URLs) | Medium |
| On-page Schema.org JSON-LD (Product, Offer, AggregateRating, BreadcrumbList) | Page interpretation + attribution readiness | Google (Search); also helpful context for other extractors | Clear entity typing; ties facts to a canonical URL; supports quotes when text matches | Incorrect or template-mismatched schema adds ambiguity fast | Medium |
| Product knowledge graph (internal canonical model) (PIM/ERP → graph view) | Consistent truth across every channel | Your systems first; downstream via feeds, pages, ads, agents, APIs | Reduces contradictions; enables relationship queries (variants, compatibility, bundles) | Higher upfront modeling cost; needs governance to stay accurate | High |
| LLM-ready structured content (definitions, spec tables, compatibility matrices) | Extraction quality + clean citations | ChatGPT, Perplexity, Claude, Gemini; also humans | Tables/definitions extract well; fewer reasoning steps required | If specs are hidden behind UI, extractors miss them | Medium |
Agent-facing index (llms.txt + curated hub pages) | Steering retrieval to the right URLs | Emerging agent tooling; some agent workflows | High signal-to-noise; reduces “wrong page” retrieval | Not a standard; only works when the underlying catalog is consistent | Low–Medium |
Next Steps
- If you need the foundation: read What is Generative Engine Optimization (GEO)? and map the cluster before you touch schema.
- If citations are the KPI: apply AI Citation Strategy: How to Get Cited by ChatGPT, Perplexity & Gemini and rewrite your top PDP and category templates around extractable facts.
- If the data layer is the bottleneck: align your internal product model with Structured Data for LLMs: Schema Markup That AI Agents Understand and Entity Density in SEO: Building Knowledge Graphs for Search, then publish the smallest set of identifiers you can keep consistent everywhere.